A C++ wrapper for QuickSched
I have introduced and mentioned the concept of task-based parallelisation a couple of times in the past, as the in my eyes most promising way to parallelise software for the exa-scale era. What I haven’t mentioned yet is that most of my mustard in this area comes from an existing C library, called QuickSched, written and developed (which in code terms are basically the same thing) by some collaborators in Durham (although none of these people are actually still in Durham).
I have used task-based parallelisation in various shapes and forms in things I have done in the past (read: I first tried using it, but got it terribly wrong, and then tried again and did a slightly better job). But for all these occasions, I started thinking about parallelisation quite late during the project and had to use my own parallelisation strategy for compatibility reasons (the typical serial code + parallelisation layer that is very common in science and the biggest obstacle towards exa-scale code), or I ended up doing something so different from what QuickSched supports that I had to write my own task-based library. Fortunately, I recently started a new project and ended up doing things right: the project only just started and I already started thinking about the parallelisation. So now I finally have an opportunity to use QuickSched as a library and exploit all its power.
There is one small complication with this however: QuickSched is written in C, while I speak C++ (not literally - yet, wait until I get Alzheimer’s). And while it’s perfectly possible to use C libraries in C++ as long as you make sure to include an extern "C" in your C header files (see a previous post), it is not ideal. Pure C code just does not feel right if all your other code uses objects. And so I ended up writing a C++ wrapper. The code is available here, below is some documentation.
Code overview
The code in the repository consists of a number of elements. First of all, there is a version of the original C QuickSched library, containing some small tweaks (like the extern "C" statements) that were required to actually use it as a library. Then, there is a number of configuration files for the CMake configuration system, ensuring that the whole library and code can be compiled using a standard cmake-make procedure. The C++ wrapper itself is contained in a single file, QuickSchedWrapper.hpp, and it is tested in testQuickSched.cpp. Finally, there is an additional Python script that can be used to make diagnostic plots.
The QuickSchedWrapper.hpp header contains four classes, three of which are meant to be exposed to the user: the QuickSched class that acts as an object-representation of the actual C library, and two abstract classes called Task and Resource that provide abstraction around the QuickSched concepts of a task and a resource. The idea is that a user inherits from these classes and then passes on her implementations to the QuickSched library object whenever a Task or Resource object is required.
The QuickSched library
Before I can show a detailed example of how the QuickSched library could be used, I need to explain what the QuickSched library actually does. In QuickSched, a computation is broken down into small parts, called tasks. Small in this case has a clear meaning: a task should both be small in terms of what it does (a small enough portion of the total computation), and what it uses (a small portion of the overall memory). These requirements are essential for proper load-balancing and efficient memory usage of the computation.
A task that is being executed will use some memory, and this particular bit of the memory is referred to as a resource for that task. A task can use memory in two ways: it can only read it, in which case it is perfectly safe for another task to read that same bit of memory simultaneously (as could happen in a parallel environment), but it can also write to it, in which case other tasks should not only not be allowed to write to it at the same time, but should also be prevented to read from it (since we don’t want ambiguity about what other tasks would read). There are hence resources that are simply used by the task, while others are effectively held by the task and are temporarily unavailable for other tasks.
In order for the entire computation to proceed correctly, resources and tasks need to be managed so that resources are accessed according to the rules above, and so that tasks are executed in an order that makes sense for the computation. If e.g. the total computation consists of computing for a large number of values and the and parts are separate tasks, then we need to make sure that the task is executed before the task for all individual values, since otherwise we would end up with instead. Note that this requirement only holds for individual elements, i.e. it is perfectly okay if tasks are executed together or before tasks, as long as they act on values for which the task already finished.
Managing tasks correctly is quite complicated, and that is where the QuickSched library comes in: it does this for you. In order to do this, it needs to know
- what resources a task requires, and whether it needs full (read/write) or partial (read only) access
- what the logical order of tasks that share resources is
In order to figure this out, QuickSched offers some functions that allow you to pass on this information. A task-based parallel simulation then consists of two stages: a serial stage during which all resources and tasks are created, and the correct information about the links between tasks and resources is fed to the library, and a parallel stage during which QuickSched executes all tasks as efficiently as possible.
The wrapper
In order to do its work, the QuickSched library requires some resources of its own. In C, these resources are managed through a manually allocated struct. The QuickSched class in the wrapper manages this struct; it creates and initialises it in its constructor, and makes sure it is correctly released in its destructor. The member functions of the QuickSched class are simple wrappers around the underlying C library functions that add the struct and additional arguments based on their C++ counterparts.
Tasks and resources in the original C library are represented by special types, which are simply typedefs for integer indices in library arrays. In the wrapper, they are replaced by the abstract classes, and these same integer indices are stored as member variables of these abstract classes. When tasks and resources are registered with the QuickSched library (through the register_task and register_resource member functions of the library object) the wrapper class will obtain the index from the C library and store it in the object. Whenever that same object is used in subsequent calls to other object member functions, it will retrieve the index from the object and use it in the C library call.
Tasks in the C library store additional information, which is required to execute the task. As is customary in C, this information is then void-wrapped and passed on to the function that is actually responsible for executing the task. It is the responsibility of this function to unwrap the additional information correctly based on the task type. This is a very non-C++ way of writing code.
What I wanted, and eventually managed to do using the Task interface in the C++ wrapper, is to put all data and functions required to execute a specific task in a single class. When the task is executed, this is simply done by calling an appropriate member function of that class, and all data that is required will be available from the class itself.
Providing such a functional mechanism can be easily achieved using C++ polymorphism: the Task class simply declares a virtual function called execute() that is then implemented by all classes that inherit from this class. If the task execution mechanism somehow were able to call the execute() function on an unspecified, general Task object, then the runtime polymorphism provided by C++ would automatically make sure the right task execution for that task data is called.
Unfortunately, the runtime polymorphism breaks down if the C++ compiler cannot determine what the type of a class is, and this information is lost when the task data is void-wrapped during the default QuickSched task execution mechanism. In order to preserve this information, I had to create an additional WrappedTask class in the C++ wrapper that simply contains an actual pointer to a Task object (not a void-wrapped pointer). By passing on this WrappedTask rather than the Task itself to the QuickSched library, the default task execution function called by the library wrapper can then unambiguously unpack the void-wrapped task data as a known WrappedTask, and then call the execute() function on the actual Task object that now can call the right version using the C++ runtime polymorphism. The user does not notice anything of this additional layer.
In the end, using the C++ wrapper becomes surprisingly straightforward. Tasks can be created as simple objects that inherit from the Task object, and only need to implement a single execute() function. Declaring resources is even easier, as a simple inheritance link in the class definition suffices to ensure that an object can be used as a resource; the library makes sure all necessary locks are created and used.
An example
In the example that is also part of the repository, the QuickSched C++ wrapper is used to compute a simple matrix project for two rather large matrices in parallel. This example does hardly explore all of the power of QuickSched (there are no task dependencies or resource conflicts), but illustrates how the library wrapper should be used.
The entire computation can be represented by a single Task object, called MatrixMultiplicationTask, that acts as both a Task and a Resource (which is allowed in C++). This object stores pointers to the two matrices that need to be multiplied, and to the matrix were the result will be stored. It also stores the matrix dimensions for convenience, and two indices that indicate a block in the matrix that will be computed by this specific task. These two indices are what makes each task unique and turns them into a resource: the indices make sure that this task is the only one that can access this specific part of the result matrix while the task is being executed.
The MatrixMultiplicationTask::execute() function simply performs the matrix multiplication for that bit of the result matrix. Since I almost literally copied this test from the original QuickSched repository, it is written in a somewhat less transparent way than I would write it, but it does work.
After setting up some variables (like the two matrices we want to multiply and the matrix where the result will be stored), the entire computation can be reduced to 6 lines of task creation (m,n,k are matrix dimensions, a,b are the input matrices and c the result matrix):
std::vector<MatrixMultiplicationTask> tasks;
for (uint_fast32_t i = 0; i < m; ++i) {
for (uint_fast32_t j = 0; j < n; ++j) {
tasks.push_back(MatrixMultiplicationTask(i, j, m, k, a, b, c));
}
}
and 7 lines of QuickSched library calls:
QuickSched quicksched(4);
for (uint_fast32_t i = 0; i < tasks.size(); ++i) {
quicksched.register_resource(tasks[i]);
quicksched.register_task(tasks[i]);
quicksched.link_task_and_resource(tasks[i], tasks[i], true);
}
quicksched.execute_tasks(4);
Here, we create a QuickSched library instance with 4 parallel queues (ideally, the number of queues should closely match the available parallel resources in the system), register the tasks and signal that the resources for each task (the task itself in this case) require full access, and then execute the entire task-based simulation using 4 parallel threads.
That’s it! After this, there is some code to clean up allocated resources (a good thing to do if you don’t like memory leaks), and some additional code to provide diagnostic output.
Task plots
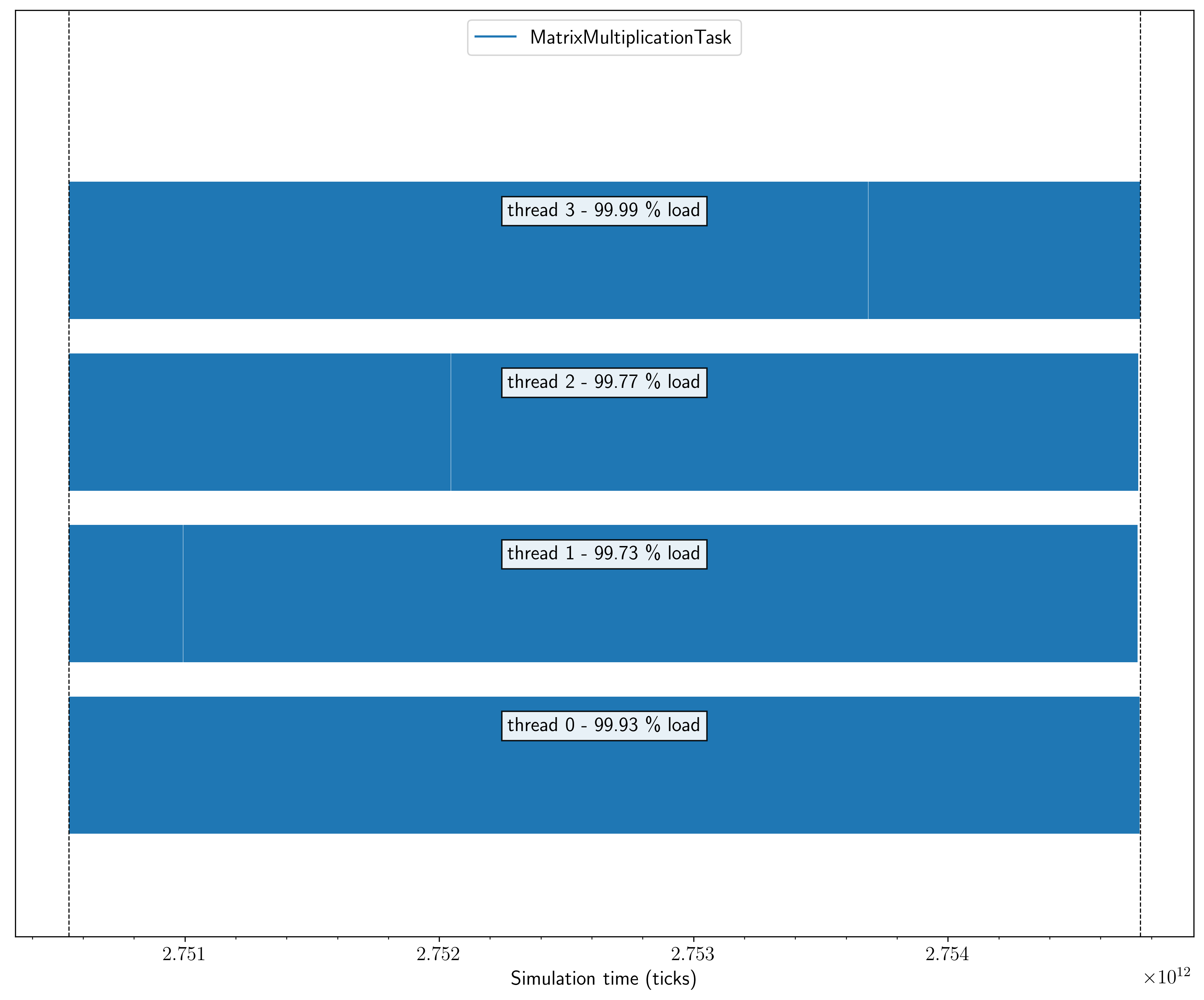
This diagnostic output is a final aspect of task-based parallelisation that I really like. Since all the computations that happen are linked to tasks, and each task is executed in a very controlled way by a single thread at a single time, it is actually surprisingly simple to keep track of how tasks are executed: we can simple record the time the task execution starts and finishes and the thread that executes it, and store these time stamps in the task data. When all tasks have finished, we can output these time stamps for all tasks, and build a full time line of how the simulation proceeded. All load-imbalances between threads will immediately show up in this time line as white patches where threads are not doing anything.
This functionality is available in the QuickSched C library, and the C++ wrapper also supports it. Whenever a task is registered with the library (using QuickSched::register_task()), the wrapper will link its class name (using the C++ typeinfo information) to a task type number that is unique for each class. It will then use that task type within the C library. The wrapper class has two functions, print_task() and print_type_dict() that can output all information to make a task plot: the former simply outputs the type number, start and end time and executing thread for the task that is provided as additional element, while the latter simply prints out the dictionary that is used internally to link type numbers and class names.
The Python script provided in the repository reads these files and turns them into a task plot, like the one for the test case shown here:
Professional astronomer.